Validating Paper-to-Skills: Double/Debiased Machine Learning Case Study
At Owkin, we believe strongly in research reproducibility. Like many academic labs, we strive to publish our methods with clean, well-documented source code whenever possible. This commitment to open science helps advance the field and enables researchers to build on each other's work.
However, the reality is that not all papers come with accessible implementations. Sometimes the core methodology lacks published code entirely. Other times, the main method is available, but important "satellite" techniques, such as data preprocessing steps, benchmarking procedures, or supplementary analyses, remain documented only in the paper's methods section.
This gap inspired us to build Paper-to-Skills, a tool that extracts methodologies from scientific papers and converts them into executable skills for AI coding agents like Claude Code.
But a critical question remained: How accurate are the extracted implementations compared to the original authors' code?
To answer this, we conducted a validation study using one of the most mathematically sophisticated papers in causal inference.
The Test Case: Double/Debiased Machine Learning
We chose to validate Paper-to-Skills with Chernozhukov et al.'s "Double/Debiased Machine Learning for Treatment and Structural Parameters" (2018, The Econometrics Journal). This paper presents a rigorous framework for estimating causal treatment effects in the presence of high-dimensional confounders: a common challenge in clinical trial analysis and observational studies.
Why this paper?
- Mathematical complexity: The methodology involves Neyman orthogonal scores, cross-fitting procedures, and influence-function-based standard errors: concepts that are theoretically deep and practically challenging to implement correctly.
- Wide adoption: The method has become a standard tool in econometrics and biostatistics, with an official Python implementation (
doublemlpackage) maintained by the original authors. - Published source code exists: This allowed us to validate our extraction against the definitive implementation, the gold standard for comparison.
Important note: When official source code exists (as in this case), we always recommend using it. This validation was specifically designed to test Paper-to-Skills' accuracy for scenarios where code is not available.
Methodology
We followed a rigorous validation protocol:
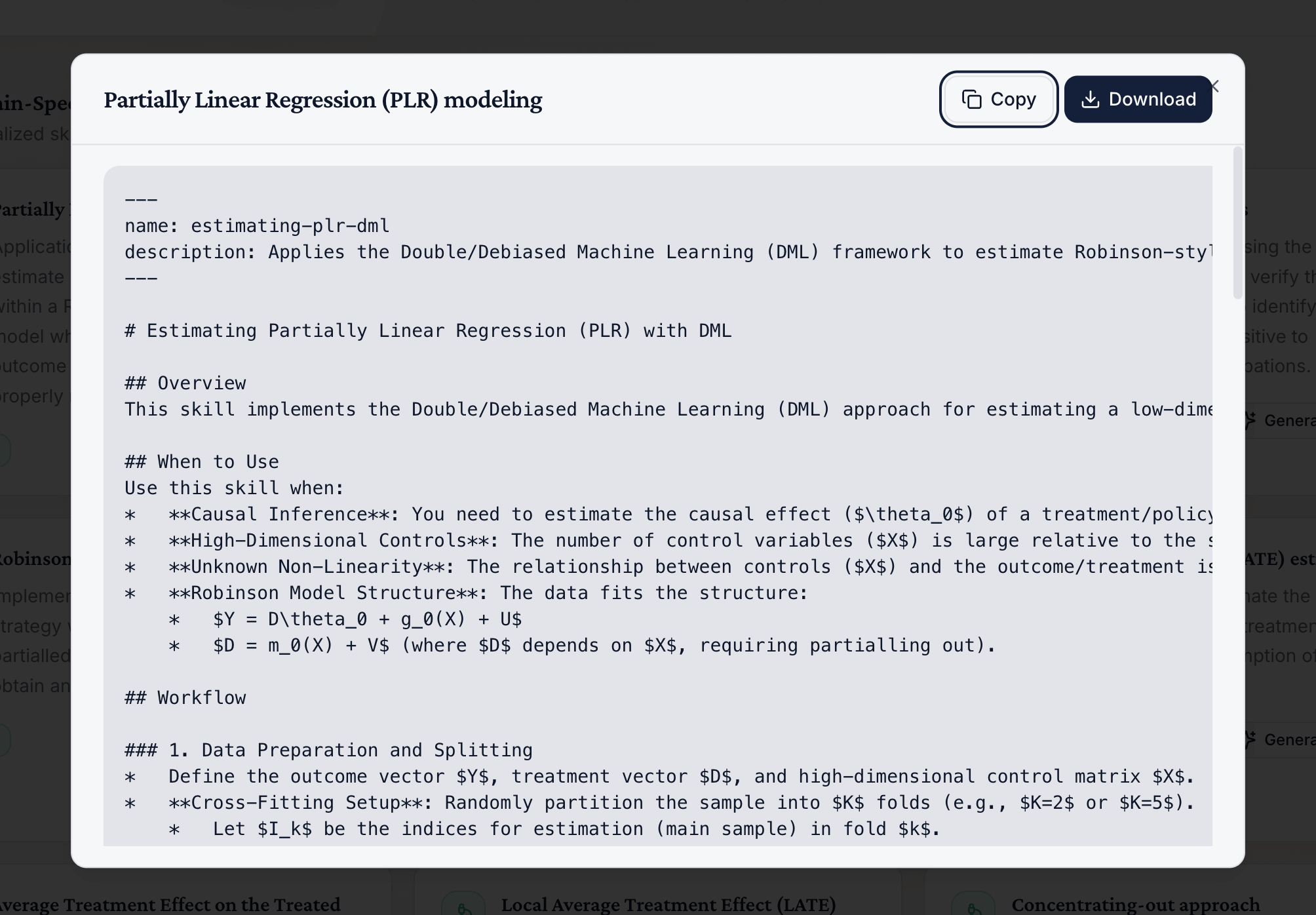
- Extraction: We used Paper-to-Skills to extract the Double/Debiased ML methodology from the Chernozhukov et al. paper, generating executable code for the Partially Linear Regression (PLR) estimator.
- Application: We applied both the Paper-to-Skills-generated code and the official
doublemlpackage to three real-world clinical trials:- ACTG 175: Large HIV clinical trial (N=2,139)
- Burn trial: Burn injury treatment study (N=154)
- Licorice trial: Licorice root for ulcer prevention (N=233)
- Comparison: We compared treatment effect estimates (θ), standard errors (SE), and p-values between both implementations.
Results
The results demonstrate remarkable concordance between the Paper-to-Skills extraction and the official implementation:
Detailed Comparison
PLR-RF: Partially Linear Regression with Random Forest for nuisance estimation
PLR-Lasso: Partially Linear Regression with Lasso for nuisance estimation
Key Observations
- Treatment effect estimates (θ) matched within 0.1-2.6% across all trials. For the largest trial (ACTG 175), the difference was just 0.07 units on an estimate of ~51.
- Standard errors were virtually identical (0.2% difference for ACTG 175).
- P-values showed slightly larger relative differences (7.9-9.9%) but remained substantively identical—both implementations led to the same statistical conclusions.
- Source of differences: The minor variations stem from random seed handling. The Paper-to-Skills implementation used a manual median-of-20 repetitions, while the
doublemlpackage uses internaln_rep=20aggregation. Both approaches are methodologically sound; the differences reflect stochastic variation, not implementation errors.

Technical Deep Dive: What Was Implemented?
The Paper-to-Skills extraction successfully reproduced several sophisticated components:
- Cross-fitting: Data splitting to avoid overfitting bias in nuisance parameter estimation
- Neyman orthogonality: Score function construction that is locally insensitive to nuisance parameter estimation errors
- Debiasing: Correction for regularization bias in machine learning estimators
- Influence function standard errors: Asymptotically valid inference accounting for estimation uncertainty
These are not trivial details. They represent the core theoretical innovations of the Chernozhukov et al. framework, and getting them right requires careful attention to the paper's mathematical exposition.
Implications
This validation demonstrates that Paper-to-Skills can accurately extract and implement complex statistical methodologies from scientific papers. The extracted code is not a rough approximation: it reproduces the mathematical framework with statistical equivalence to expert-maintained implementations.
When to Use Paper-to-Skills vs. Official Code
Use official implementations when available:
- They represent the authors' definitive implementation
- They're maintained and updated
- They're the standard for reproducibility and methods comparisons
Use Paper-to-Skills when:
- No official implementation exists for the method
- You need satellite techniques (preprocessing, benchmarking) not covered in the code
- You want to quickly prototype or understand a method before committing to a full implementation
- You're working with legacy papers where code has been lost or deprecated
Conclusion
The Double/Debiased ML validation demonstrates that Paper-to-Skills can reliably extract sophisticated methodologies from scientific papers and generate code that matches expert implementations. While we always recommend using official source code when available, this validation gives us confidence that Paper-to-Skills fills a genuine gap for methods where code is unavailable.
We're continuing to test and improve Paper-to-Skills across diverse domains such as bioinformatics, computational biology, machine learning, and beyond. The tool is currently in beta, and we welcome feedback from the research community.
Try Paper-to-Skills: https://paper2skills.com
Reference:
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, James Robins. "Double/debiased machine learning for treatment and structural parameters." The Econometrics Journal, Volume 21, Issue 1, February 2018, Pages C1–C68. https://doi.org/10.1111/ectj.12097
Authors


Testimonial
